Summary
论文 1:¶
BAFN: Bi-Direction Attention Based Fusion Network for Multimodal Sentiment Analysis¶
BAFN:基于双向注意力的多模态情感分析融合网络
Abstract
本文主要研究了多模态情感分析中的注意力网络。文章中指出,现有的方法忽略了辅助模态的冗余性,只关注自上而下的注意力(静态过程)或自下而上的注意力(隐式过程),导致了多模态情感上下文的粗粒度。为了解决这个问题,作者首先提出了多模态动态增强块来捕获内模态情感上下文,有效地减少了辅助模态的内模态冗余性。然后,提出了双向注意力块,通过新颖的双向多模态动态路由机制来捕获细粒度的多模态情感上下文。具体来说,双向注意力块首先突出显示明确和低级别的多模态情感上下文,然后将低级别的多模态上下文传输到精心设计的双向多模态动态路由过程中。这使模型能够动态更新和研究高级别和更细粒度的多模态情感上下文。实验结果表明,融合网络可以达到最先进的性能。值得注意的是,模型在“Acc-7”指标上超过了最好的基线,提高了6.9%。
Keywords
Multimodal fusion network, multimodal sentiment analysis, attention mechanism、
Related Work
在非注意力基础的多模态学习中,LSTM和RNN技术在多模态情感分析中引起了广泛关注,因为它们在利用序列的时间相关性方面表现出色。例如,BC-LSTM提出了双向LSTM以突出模态话语之间的情感属性。RMFN使用RNN将复杂的多模态融合过程分解为几个融合子阶段,从而导致更复杂的多模态相互关系。此外,还有一些模型,如MV-LSTM,Self-MM,MFM,ICCN,ERLDK,混合深度模型等,都在这个领域做出了贡献。然而,这些网络未能有效地从长序列中探索多模态情感上下文,这可能限制了学习模型的表达能力。
在基于注意力的多模态学习中,与上述模型相比,基于注意力的框架在分析长序列表示方面表现出了优越性。例如,MMLGAN提出了一种多模态局部-全局注意网络,以整合不同模态的表示,从而产生一个有区别的情感表示。MARN利用多注意力块同时研究每个时间步骤中的多个跨模态情感上下文,然后将情感上下文存储在混合内存块中。此外,还有一些模型,如RAVEN,MAG,MFN,MISA,MulT,MCTN等,都在这个领域做出了贡献。然而,现有的多模态情感分析网络忽视了辅助模态(音频和视频)的冗余,这增加了有效推理多模态情感上下文的难度。
总的来说,这些工作都在多模态情感分析领域做出了贡献,但都存在一些局限性,如未能有效地从长序列中探索多模态情感上下文,或忽视了辅助模态的冗余等。
Content
方法主要包括两个部分:多模态动态增强块(Multimodal Dynamic Enhanced Block)和双向注意力块(Bi-direction Attention Block)。
1、多模态动态增强块:
这个部分主要用于预处理阶段,通过更具区分性的模态(文本)动态捕获辅助模态(音频和视频)的内模态情感上下文。这样可以有效地减少辅助模态的内模态冗余,从而获得更具区分性的音频和视频。然后,这些更具区分性的辅助模态被传输到双向注意力块。这个块包含M个处理头,每个头包含N个自适应迭代。每个自适应迭代都试图通过更具区分性的模态(文本)从音频(视频)模态中获取内模态上下文。然后,多个堆叠的迭代专注于动态更新或修改内模态情感上下文,从而产生更具区分性的音频(视频)模态。相比于与多个动态迭代相关联的单头情况,多头情况可以获得更好的任务性能。
2、双向注意力块:
这个部分首先通过静态多模态处理捕获显式和低级的多模态情感上下文。然后,上述低级多模态上下文被传输到与多个迭代相关联的精心设计的多模态动态路由过程。赋予了多模态融合网络动态更新和研究更细粒度多模态情感上下文的强大能力。
论文 2:¶
Countering Modal Redundancy and Heterogeneity: A Self-Correcting Multimodal Fusion¶
对抗模态冗余和异质性: 自校正多模态融合
Abstract
文章主要讨论了多模态异构数据融合在各个领域(如动作识别和交通事故预测)的重要性。然而,异构特征交互和特征冗余等关键挑战显著影响了多模态融合的性能。为了解决这些挑战,作者首先设计了一个统一特征交互模块(UFIM),其中设计了一个新的正交注意力组件,用于获取异构特征之间的精细的跨模态交互信息。然后,他们提出了一个新的自我纠正变压器模块(SCTM),该模块使用修改后的变压器获取当前模态特征与其他模态合并特征之间的一对多关联信息,以减轻冗余问题。在四个跨领域任务上的大量实验证明了他们提出的方法的有效性和泛化能力。
Keywords
multimodal fusion, redundancy, heterogeneity, feature interaction, transformer
Related Work
首先介绍了多模态的集中思路:
1、早期融合:
早期融合方法试图通过单一网络实现多模态识别或预测,它在特征级别对多个输入进行预处理,如特征连接。这种方法高度依赖于多模态是否可以直接连接,可能导致模态上下文丢失。
2、晚期融合:
晚期融合方法为每种模态建立单独的模型,并在模型级别进行融合。这种方法确保了模态信息的全面提取,并且几乎不依赖于多模态是否可以直接连接。然而,现有的晚期融合方法在融合过程中没有考虑到模态间的交互问题,这与多模态融合的原始意图是相反的。
3、中间融合:
中间融合方法试图在中间阶段实现多模态特征交互,专注于建模内部和模态间的动态。然而,所有这些现有的方法通常都基于一个理想化的假设,即所有模态都在一个类似的语义空间中,即提取的多模态特征可以直接连接。然而,在现实场景中,由于各种数据收集方式,无法避免模态间的语义差距。
最近,注意力机制被应用于多模态融合中,以实现精确的融合表示。例如,一些先驱工作直接将注意力机制应用于高级特征以完成视频相关任务。另一些工作提出了一个深度敏感的注意力模块,以显式消除在显著性检测中的背景干扰。然而,所有的预处理方法,包括早期融合和中间融合,都假设所有模态都在一个类似的语义空间中,最终都会导致模态冗余的问题。
Content
文章中提到的方法主要包括统一特征交互模块(UFIM)和自我纠正变压器模块(SCTM)。
1、统一特征交互模块(UFIM):
这个模块修改了传统的Transformer机制,以实现模态特征的传递。它的多头注意力机制接收两种模态作为输入。具体来说,为了实现模态特征的传递,作者首先定义X'为Q(Query),Y'为K(Key)和V(Value),并使用T来提取信息M'X。这里的M'X表示X'对Y'的信息感兴趣,同样,M'Y表示Y'对X'的信息感兴趣。提取公式如下:
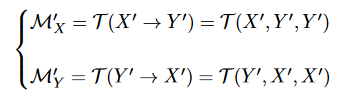
此外,为了赋予T区分不同模态的能力,作者在传统的位置嵌入中额外嵌入了模态身份信息。注意,模态身份信息,表示当前正在处理的主要模态,只由Q决定。也就是说,输入到T的Q、K和V的模态身份信息是相同的。
UFIM设计了一个正交注意力组件,用于获取异构特征之间的细粒度交互信息。通过其内置的正交注意力和交互反馈,UFIM能够有效地提取和传递特征之间的细粒度关系,实现统一的模态交互。与传统的全局平均池化和基于连接的方法相比,细粒度信息可以有助于结构化特征的提取。
2、自我纠正变压器模块(SCTM):
这个模块用于纠正特征融合前后的冗余。在SCTM的交互反馈阶段,权重α用于控制基于细粒度注意力的表示对最终融合表示的影响。
SCTM采用修改后的变压器来获取当前模态特征与其他模态合并特征之间的一对多关联信息,以缓解冗余问题。通过使用这些关注点纠正两个模态,我们可以减轻无关和重复信息。纠正后的特征被用作任务特定融合模块的输入,该模块通过融合表示纠正策略获得最终的融合表示。
这两个模块共同解决了多模态融合中的异质性和冗余性问题。UFIM主要解决异质性问题,而SCTM则主要解决冗余性问题。两种方法的结合使得多模态融合能够更有效地处理异构数据,从而在各种任务,如动作识别和交通事故预测等,上表现出更好的性能。
论文 3:¶
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection¶
DeepFusion: 用于多模态三维物体检测的激光雷达-摄像头深度融合技术
Abstract
文章主要研究了激光雷达和相机在自动驾驶中的3D检测应用。尽管现有的多模态方法通常只是用相机特征装饰原始激光雷达点云,并直接将它们输入到现有的3D检测模型中,但作者的研究表明,将相机特征与深度激光雷达特征(而不是原始点)融合,可以提高性能。然而,由于这些特征通常会被增强和聚合,融合中的一个关键挑战是如何有效地对齐两种模态的转换特征。因此,作者提出了两种新颖的技术:InverseAug和LearnableAlign。基于这两种技术,作者开发了一系列名为DeepFusion的通用多模态3D检测模型,其精度超过了以前的方法。例如,DeepFusion在行人检测上改进了PointPillars、CenterPoint和3D-MAN基线,分别提高了6.7、8.9和6.2的LEVEL_2 APH。值得注意的是,作者的模型在Waymo开放数据集上取得了最先进的性能,并显示出对输入腐败和分布外数据的强大模型鲁棒性。
Related Work
1、3D Object Detection on Point Clouds:
许多3D对象检测方法直接处理无序的点云数据。早期的开创性工作如PointNet和PointNet++直接在点云上应用神经网络。后续的一些研究也使用了类似PointNet的层来学习特征。雷达点云也可以被表示为密集的范围图像,每个像素包含额外的深度信息。另一种3D检测方法是将雷达点转换为体素或柱子,这导致了两种更常用的3D检测方法:基于体素和基于柱子的方法。VoxelNet提出了一种基于体素的方法,该方法将点云离散化为3D网格,每个子空间被称为一个体素。然后可以将密集的3D卷积网络应用到这个网格上来学习检测特征。SECOND在VoxelNet的基础上提出使用稀疏3D卷积来提高效率。由于3D体素通常很难处理,PointPillars和PIXOR进一步将3D体素简化为鸟瞰视图的2D柱子,所有具有相同z轴的体素都被折叠到一个柱子上。这些2D柱子然后可以用现有的2D卷积检测网络处理,以产生鸟瞰视图的边界框。
2、Lidar-camera Fusion:
一些方法首先在2D图像中检测对象,然后使用这些信息进一步处理点云。先前的一些工作也使用了两阶段的框架来进行对象中心的模态融合。与这些方法相比,我们的方法更容易插入到大多数现有的基于体素的3D检测方法中。
3、Point Decoration Fusion:
PointPainting提出了一种方法,用预训练的语义分割网络从相机图像中提取的语义分数来增强每个雷达点。PointAugmenting指出了语义分数的限制,并提出了一种方法,用从相机图像上的2D对象检测网络中提取的深度特征来增强雷达点。
4、Mid-level Fusion:
Deep Continuous Fusion、EPNet和4D-Net试图通过在2D和3D主干之间共享信息来融合两种模态。然而,这些工作中缺少的一个重要部分是相机和雷达特征之间的有效对齐机制,这在我们的实验中被证实是构建一个有效的端到端多模态3D对象检测器的关键。
Content
文章中提出了一种名为DeepFusions的多模态3D检测模型,以解决3D物体检测中的一些挑战。这种模型主要解决了两个问题:一是如何有效地融合激光雷达和相机的特征,二是如何提高模型对远距离物体的识别和定位能力。
为了解决这些问题,文章提出了两种技术:InverseAug和LearnableAlign。
1、InverseAug:
这种技术旨在解决数据增强带来的问题,灵感来自于 PPBA,它在训练过程中对激光雷达点云应用以下数据增强策略:RandomRotation → WorldScaling → GlobalTranslateNoise → RandomFlip → FrustumDropout → RandomDropLaserPoints。与 PPBA 和其他工作不同的是,这里我们保存所有几何相关数据增强(即,RandomRotation, WorldScaling, GlobalTranslateNoise, RandomFlip)的所有随机生成参数。在融合阶段,我们使用保存的参数反向应用所有这些增强,以找到在应用数据增强之前的原始3D坐标系统中的坐标。此外,我们还需要反转增强的顺序。
在训练模型时,通常会对数据进行各种增强(例如,随机旋转),以提高模型的泛化能力。然而,这种增强可能会改变激光雷达和相机数据之间的对应关系,从而影响模型的性能。InverseAug通过反转与几何相关的数据增强(例如,RandomRotation),然后使用原始的相机和激光雷达参数来关联两种模态,从而解决了这个问题。
2、LearnableAlign:
这种技术旨在解决激光雷达和相机特征之间的对齐问题。在多模态3D物体检测中,找出激光雷达和相机特征之间的对应关系是一个重要的挑战。LearnableAlign利用交叉注意力机制动态捕获两种模态之间的关联。具体来说,输入包含一个体素单元和所有对应的 N 个相机特征。LearnableAlign 使用三个全连接层分别将体素转换为查询 ql,以及相机特征转换为键 kc 和值 vc。对于每个查询(即,体素单元),我们在查询和键之间进行内积,得到注意力亲和矩阵,该矩阵包含 1 × N 个体素和所有对应的 N 个相机特征之间的关联。通过 softmax 操作符进行归一化,注意力亲和矩阵用于权重和聚合包含相机信息的值 vc。聚合的相机信息然后被一个全连接层处理,并最终与原始的激光雷达特征进行连接。输出最后被送入任何标准的3D检测框架,如 PointPillars 或 CenterPoint 进行模型训练。
这两种技术都是简单、通用且高效的,可以轻松地应用到大多数基于体素的3D检测方法,如PointPillars和CenterPoint。目标都是在深度特征层面实现有效的对齐。通过使用这两种技术,DeepFusions模型能够有效地融合激光雷达和相机的特征,从而显著提高了模型的识别和定位能力,特别是对于远距离物体的检测。
论文 4:¶
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering¶
学会解释:通过思维链进行多模态推理以回答科学问题
Abstract
文章介绍了一个名为科学问题回答(SCIENCEQA)的新基准测试,它包含了21k个多模态选择题,涵盖了多样化的科学主题,并对其答案进行了注解,包括对应的讲座和解释。作者设计了语言模型,学习生成讲座和解释作为思维链(CoT),以模拟回答SCIENCEQA问题时的多跳推理过程。研究表明,语言模型从解释中受益,可以通过更少的数据学习,并且只需要40%的数据就能达到相同的性能。该论文探讨了在科学问题回答的背景下,是否可以赋予机器推理能力。
Content
文章的主要成果如下:
- 该研究开发了一个名为Science Question Answering (SCIENCEQA)的新数据集,该数据集包含21,208个多模态科学问题,涵盖了丰富的领域多样性。据作者所知,SCIENCEQA是首个大规模的多模态数据集,为答案注释了讲解和解释。
- 模型可以生成合理的解释,根据自动化指标进行评估,65.2%的解释达到了人类评估的黄金标准。他们还研究了模型利用解释的上限,通过将解释包含在输入中,发现这样做可以提高GPT-3的少数样本性能18.96%,这表明解释确实有助于模型,并且在CoT框架中目前被低估了。
- 进一步分析显示,像人类一样,语言模型从解释中受益,可以用更少的数据进行学习:UnifiedQA使用CoT可以获得与没有CoT的UnifiedQA相同的结果,只需要40%的训练数据。
- 研究还发现,GPT-3(CoT)可以预测正确的答案,并生成合理的讲解和解释,以模仿人类的思维过程。
- 他们的研究还提供了一些失败的例子,这些例子中,预测的答案是错误的。他们将这些图像的标题提取出来,并将它们作为视觉内容输入。然而,这些标题缺乏细粒度的语义,通常对于图表不太有效,这导致了两个失败的案例。此外,对于需要理解复杂和不常见领域知识的问题,大型语言模型存在挑战。例如,GPT-3(CoT)不能准确理解“多选题”的术语。
- 该研究的SCIENCEQA数据集和设计的方法对后续的研究工作和实际应用都有益。SCIENCEQA为多模态学习、多跳推理和通用人工智能提供了有用的基准。此外,SCIENCEQA将有助于K-12教育应用的开发,如辅导系统。此外,他们设计的方法通过思维链探索了大型语言模型在推理复杂任务时模仿人类思维过程的能力。
Dataset
SCIENCEQA数据集包含21,208个多模态科学问题,涵盖了丰富的领域多样性。据作者所知,SCIENCEQA是首个大规模的多模态数据集,为答案注释了讲解和解释。数据集的问题主要来源于教科书,旨在诊断AI系统的多模态理解和多跳推理能力。由于数据来源的性质,SCIENCEQA不包含任何用户使用数据或个人敏感信息,如性别和种族。
论文 5:¶
D-vlog: Multimodal Vlog Dataset for Depression Detection¶
D-vlog:用于抑郁检测的多模态 Vlog 数据集
Abstract
文章主要研究了激光雷达和相机在自动驾驶中的3D检测应用。尽管现有的多模态方法通常只是用相机特征装饰原始激光雷达点云,并直接将它们输入到现有的3D检测模型中,但作者的研究表明,将相机特征与深度激光雷达特征(而不是原始点)融合,可以提高性能。然而,由于这些特征通常会被增强和聚合,融合中的一个关键挑战是如何有效地对齐两种模态的转换特征。因此,作者提出了两种新颖的技术:InverseAug和LearnableAlign。基于这两种技术,作者开发了一系列名为DeepFusion的通用多模态3D检测模型,其精度超过了以前的方法。例如,DeepFusion在行人检测上改进了PointPillars、CenterPoint和3D-MAN基线,分别提高了6.7、8.9和6.2的LEVEL_2 APH。值得注意的是,作者的模型在Waymo开放数据集上取得了最先进的性能,并显示出对输入腐败和分布外数据的强大模型鲁棒性。
Abstract
文章主要研究了如何通过多模态的vlog数据集来检测抑郁症。文章首先介绍了抑郁症的严重性和普遍性,以及目前对抑郁症的诊断主要依赖于临床医生的主观判断,这种方法存在一定的局限性。因此,研究者们提出了一个新的方法,即通过分析vlog(视频博客)中的多模态数据(包括文本、音频和视频)来检测抑郁症。文章中,作者们提出了一个名为"D-vlog"的数据集,这是一个包含了大量vlog的数据集,这些vlog来自于公开的网络平台,如YouTube。这些vlog中的人物都有抑郁症的症状,因此这个数据集可以用来训练和测试抑郁症检测的算法。文章还详细介绍了如何从vlog中提取多模态数据,包括文本、音频和视频数据,并且如何使用这些数据来训练和测试抑郁症检测的算法。此外,文章还讨论了这种方法的有效性和潜在的应用。
总的来说,这篇文章提出了一个新的抑郁症检测方法,即通过分析vlog中的多模态数据来检测抑郁症,这种方法有可能改变抑郁症的诊断方式,使其更加客观和准确。
Related Work
1、Datasets for Depression Analysis and Detection:
文章指出,目前存在一些公开的抑郁症数据集,但这些数据集大多在实验室环境中通过访谈形式收集,可能无法捕捉到抑郁个体在日常生活中的常态行为。因此,作者们提出了一个新的抑郁症数据集,该数据集包括在日常生活中捕捉到的抑郁个体的非言语行为。具体来说,他们首先使用如“抑郁症vlog”、“日常vlog”等搜索关键词收集了抑郁和非抑郁个体的vlog,然后根据开发的注释规则(例如,“给定的视频是否有vlog格式?”、“说话者是否正在遭受抑郁症?”等)手动注释了抑郁和非抑郁的vlog,并从中提取了声音和视觉特征。由于vlog是自愿录制和上传的,作者们认为他们的数据集包含的抑郁相关特征与非抑郁者的特征相比,比实验室环境中收集的先前数据集更自然。
2、Detecting Depression Using Social Media Data:
文章提到,学者们已经开发了基于社交媒体数据(如文本、图片和标签)的抑郁症检测模型。例如,Wang等人(2013)提出了一个使用Sina Weibo中的标签和文本的抑郁症检测模型。他们根据关于抑郁症的心理理论提取了基于内容、交互和行为的特征来训练模型。Gui等人(2019)应用了合作多代理强化学习方法,基于文本和图像特征识别Twitter用户的抑郁症。Orabi等人(2018)提出了一个词嵌入优化方法,并将其应用于检测Twitter上的抑郁个体。虽然这些研究都关注了使用社交媒体数据检测抑郁症,但对如何使用社交媒体上的视频数据检测抑郁症的模型和分析却没有给予足够的关注,这些视频数据可以捕捉到日常生活中的常态行为。
3、Multimodal Fusion:
多模态融合的目标是整合来自多种模态的信息以预测目标输出。在多模态融合的先前工作中,大多依赖于模型不可知的方法,如早期融合、晚期融合和混合融合。学者们通过简单地连接、添加或乘以特征/决策级向量来创建多模态表示,以执行预测任务。随着深度学习技术的进步,神经网络可以用于多模态融合。这些工作使用深度神经网络(如LSTM)来通过从多种模态生成联合表示来描述目标。为了有效地利用和融合多模态数据,我们采用了跨注意力机制来融合多模态信息。
Depression Vlog (D-Vlog) Dataset
该部分主要介绍了 D-Vlog 数据集的构建过程和特性。以下是该部分的主要内容:
- 数据收集:作者的目标是构建一个包含抑郁和非抑郁vlog的平衡数据集,以帮助模型学习与非抑郁特征明显不同的独特抑郁相关特征。为此,他们首先使用如“抑郁日常vlog”、“抑郁旅程”、“抑郁vlog”、“抑郁发作vlog”、“抑郁视频日记”、“我的抑郁日记”和“我的抑郁故事”等搜索关键词收集了YouTube视频。对于非抑郁vlog,他们使用了“日常vlog”、“准备就绪的我vlog”、“购物vlog”、“如何vlog”、“一天的vlog”、“谈话vlog”等关键词。使用这两种类型的关键词集,他们下载了4000个视频(即每种类型2000个视频),这些视频是从搜索结果中随机选择的。
- 数据标注:为了将收集的视频标记为抑郁和非抑郁vlog,他们招募了四名大学生。他们教育标注者使用标注规则和样本视频,以确保所有vlog的标注质量相似。他们为每个标注者分配1000个视频(即每个标签500个vlog),并要求他们完成两项任务。首先,标注者确定给定的视频是否有“vlog”格式,即一个人直接对着摄像头讲话。也就是说,他们移除了不符合“vlog”格式的视频(例如,一群人,视频中没有面孔),以便从视频中的人物提取声音和视觉特征。接下来,标注者仔细观看带有自动生成字幕的视频,以确定视频中的演讲者是否有抑郁症。需要注意的是,他们只考虑英文视频,因为标注者需要理解单词的上下文。
- 数据统计:他们在表2中提供了最终标注数据集的描述性统计信息。数据集由555个抑郁vlog和406个非抑郁vlog组成,平均长度分别为640.12秒和536.38秒。他们发现在抑郁vlog中,女性的数量是男性的两倍,这与之前的工作显示的主要抑郁症患者中女性比例较高的结果一致。
- 特征提取:对于声音和视觉特征,他们都将时间步长截断或用零填充,使所有样本的长度都相同。为了去除数据集中每个演讲者的身份,他们只提供提取的特征,而不提供音频和视频文件。因此,无法通过这些特征识别个体。他们遵循了由机构审查委员会(IRB)指导的所有匿名化过程。
Multimodal Depression Detection
- 多模态融合:多模态融合的目标是整合来自多种模态的信息以预测目标输出。以前的多模态融合工作主要依赖于模型不可知的方法,如早期融合,晚期融合和混合融合。学者们通过简单地连接、添加或乘以特征/决策级向量来创建多模态表示以执行预测任务。随着深度学习技术的进步,神经网络可以用于多模态融合。这些工作使用深度神经网络(例如,长短期记忆网络)来通过从多种模态生成联合表示来表征目标。在这个模型中,作者们采用了跨注意力机制来有效地捕捉声学和视觉特征之间的关系,并生成有用的多模态表示用于抑郁症检测。
- 抑郁症检测模型:抑郁症检测模型使用了非语言特征,即声学和视觉特征,从给定的视频中提取。该模型使用Transformer编码器来编码声学和视觉序列,并使用交叉注意力机制来融合它们,以生成用于抑郁症检测的表示。最后,抑郁症检测层预测vlog的抑郁症标签。此外,该模型使用了单模态Transformer编码器来生成每个输入模态的表示。因此,该模型不仅限于声学和视觉特征,任何其他模态都可以通过使用单模态编码器简单地添加。为了模型化序列输入数据,他们首先对特征向量进行下采样,通过应用一维卷积层处理局部关系,并使用位置编码层。然后,他们使用了原始的Transformer编码器,该编码器由自注意力和前馈层组成。由于自注意力层引导单模态Transformer编码器关注每个模态内的重要线索,单模态表示可以使模型捕获用于抑郁症检测的有用知识。这个模型的开发是基于这样的观察,即抑郁症和非抑郁症的个体可以通过非语言信号,如面部表情、身体动作和声音强度来区分。因此,这个模型试图利用这些非语言信号来检测抑郁症。
- 实验结果:广泛的实验结果表明,提出的模型显著优于其他基线模型。作者认为他们的数据集和提出的模型对于基于非语言行为分析和检测抑郁症的个体是有用的。
Created: 2023-07-29