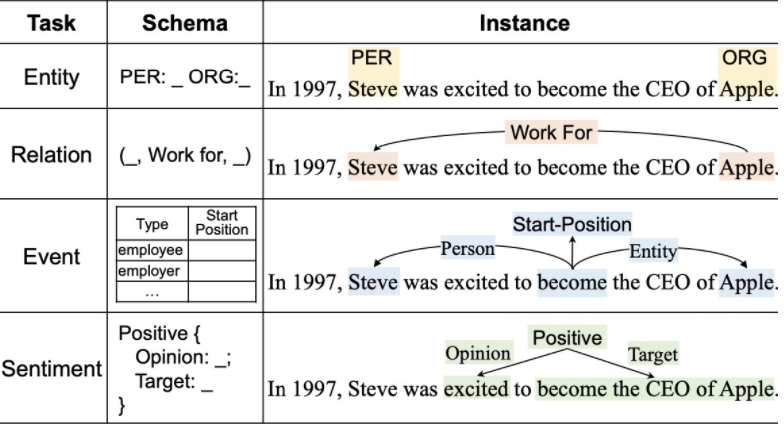
信息抽取¶
信息抽取旨在从无结构的自然语言文本中抽取出结构化的信息
-
知识抽取最重要的 4 个子任务:
-
实体抽取 (识别):命名实体识别,包括实体的检测与分类,一般 span 及其实体类别表示
-
关系抽取:一般 triplet 表示
-
事件抽取:多元关系,一般 record表示
-
观点抽取:一般 triplet 表示
-
-
相关竞赛、数据集:
- ACE:对 MUC 定义任务进行融合
- KBP:四个独立任务、一个整合任务
- SemEval:词义消歧评测
相关会议/数据集:MUC、ACE、KBP、SemEval、TREC etc.
实体抽取¶
实体抽取/命名实体识别 (NER) ,主要抽取的文本中的原子信息元素 (人名、组织/机构名、地理位置、事件/日期、字符值、金额值 etc.)。其关键词可以总结为两个:find & classify,即 find 文本中的 entity,再对其进行分类。
主要应用¶
- 命名实体用于索引与超链接
- 数据分析的准备步骤
- 关系抽取的准备步骤
- QA 系统的答案形式大多都为命名实体
抽取方法¶
Traditional Machine Learning¶
大致流程
Training
- 收集对应的训练文档
- 为每个 token 标记命名实体
- 设计特征提取方法
- 训练 sequence classifier 预测数据的 label
Testing
- 收集对应测试文档
- 运行 sequence classfier 标记 token
- 输出命名实体
标注与编码
进行数据标注时,最常用的有两种 sequence labeling 的编码方式:IO/IOB encoding
对于 IO,若单词不为命名实体 (NE) 就标为 O (other)
对于 IOB,使用 I-PER 承接上一个 NE,若连续出现两个B-PER,则上一个 B 结束
Sequence model¶
常见的序列模型有:
- 有向图模型:如 HMM,生成式模型,假设特征之间相互独立,找到使得 P(X|Y) 最大的参数
- 无向图模型:如 CRF,判别式模型,没有特征独立的假设,找到使得 P(X|Y) 最大的参数
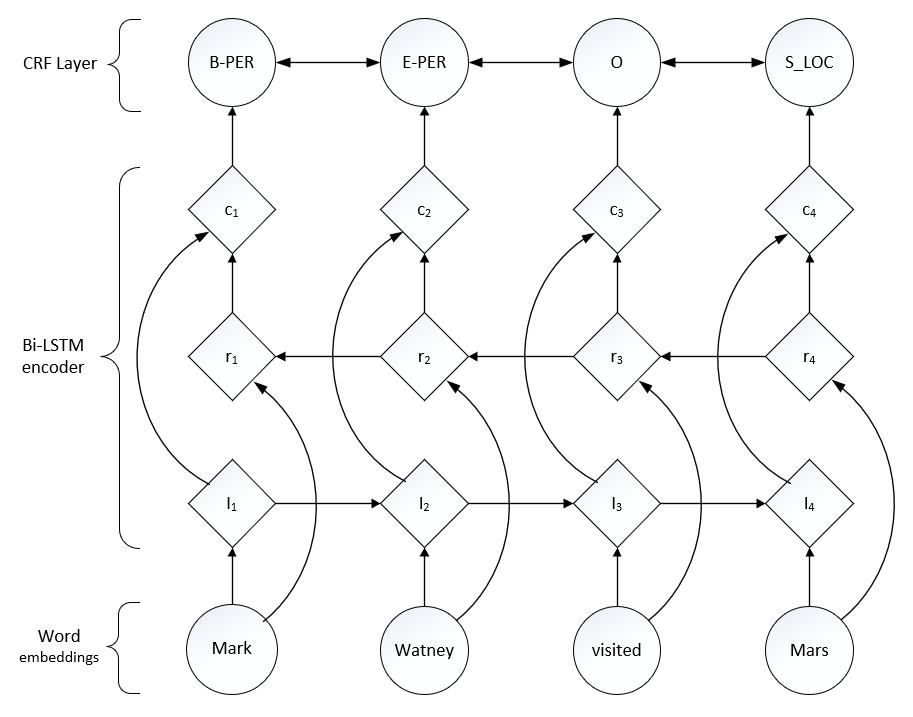
Deep Learning¶
LSTM + CRF
端到端的判别式模型,LSTM 利用过去的输入特征,CRF 利用句子级的标注信息,有效利用过去与未来的标注预测当前标注。
关系抽取¶
关系抽取 需要从文本中抽取两个/多个实体之间的语义关系,主要方法有:
- 基于模板的方法 (hand-written patterns)
- 基于触发词/字符串
- 基于依存句法
- 监督学习 (supervised machine learning)
- Machine Learning
- Deep Learning
- 半监督/无监督学习 (semi-supervised / unsupervised learning)
- Bootstrapping
- Distant supervision
- Unsupervised learning from the web
基于模板的方法¶
基于触发词/字符串¶
首先是 基于字符串的 pattern,例如 IS-A 关系
Agar is a substance prepared from a mixture of red algae, such as Gelidium, for laboratory or industrial use
基于 such as,可以判断其为 IS-A 关系,由此可以写出的规则为:
“Y such as X ((, X)* (, and|or) X)”
“such Y as X”
“X or other Y”
“X and other Y”
“Y including X”
“Y, especially X”
其次对于特定实体,有 基于 NER 的 pattern,使用 NER 标签帮助进行关系抽取
• located-in (ORGANIZATION, LOCATION)
• founded (PERSON, ORGANIZATION)
• cures (DRUG, DISEASE)
当然,也可以结合两种 pattern,对应的工具有 Stanford CoreNLP 的 tokensRegex
基于依存句法¶
通常可以以动词为起点构建规则,对节点上的词性和其边上的依存关系进行限定,流程为:
- 对句子进行分词、词性标注、命名实体识别、依存分析等处理
- 根据句子依存语法树结构上匹配规则,每匹配一条规则就生成一个三元组
- 根据拓展规则对抽取到的三元组进行拓展
- 对三元组实体和触发词进一步抽取出关系
监督学习¶
Machine Learning¶
Feature
对于文本:
American Airlines, a unit of AMR, immediately matched the move, spokesman Tim Wagner said
Mention 1 (M1):American Airlines
Mention 2 (M2):Tim Wagner
常用的 Feature 有:
Word Features
- M1 与 M2 的词条 (headwords) 及其组合 (combination)
- 例,M1:Airlines,M2:Wagner,Combination:Airlines-Wagner
- M1 与 M2 中的词袋 (Bag of words) 与二元组 (bigrams)
- {American, Airlines, Tim, Wagner, American Airlines, Tim Wagner}
- M1/M2 左右特定位置的单词或二元组
- M2: -1 spokesman
- M2: +1 said
- 两个实体之间的词袋或二元组
- {a, AMR, of, immediately, matched, move, spokesman, the, unit}
Named Entities Type and Mention Level Features
- 命名实体 (NE) 类型
- M1: ORG
- M2: PERSON
- 2 命名实体的关联 (Concatenation)
- ORG-PERSON
- M1 与 M2 的实体级别 (NAME, NOMINAL, PRONOUN)
- M1: NAME [it or he would be PRONOUN]
- M2: NAME [the company would be NOMINAL]
Parse Features
- 词到词的基本句法块序列 (Base syntactic chunk sequence)
- NP NP PP VP NP NP
- 树到树的构成路径 (Constituent path)
- NP ↑ NP ↑ S ↑ S ↓ NP
- 依赖路径 (Dependency path )
- Airlines matched Wagner said
Gazetteer and trigger word features
- 家庭触发列表:亲属关系术语
- parent, wife, husband, grandparent, etc.
- 地名词典
- List of useful geo or geopolitical words
- Country name list
- Other sub-entities
Classification
分类器流程:
- 预先定义好想提取的关系集合
- 选择相关的命名实体集合
- 寻找并标注数据
- 选择有代表性的语料库
- 标记命名实体
- 人工标注实体间的关系
- 分成训练、开发、测试集
- 设计特征
- 选择并训练分类器
为了提高 efficiency,通常会训练两个分类器,第一个分类器是 yes/no 的二分类,判断命名实体间是否有关系,如果有关系,再送到第二个分类器,给实体分配关系类别。这样做的好处是通过排除大多数的实体对来加快分类器的训练过程,另一方面,对每个任务可以使用 task-specific feature-set
可以采用的分类器可以是 MaxEnt、Naive Bayes、SVM 等。
Deep Learning¶
DL 方法分为两类:Pipeline 与 Joint Model
常用特征有:
- Position embeddings
- Word embeddings
- Knlowledge embeddings
模型通常有 CNN / RNN + attention,损失函数一般 ranking loss 要优于交叉熵
Pipeline
将实体识别与关系分类作为两个完全独立的过程,不会相互影响,关系的识别判断依赖于实体识别的效果
如:CR-CNN、Att-CNN、Att-BLSTM
Joint Model
实体识别与关系分类的过程共同优化
如:LSTM-RNNs
半监督/无监督学习¶
半监督学习¶
半监督学习主要是利用少量的标注信息进行学习,该方面主要基于 Bootstrap (引导) 的方法,以及 distant supervision (远程监督) 方法。基于 Bootstrap 的方法主要是利用少量实例作为初始种子 (seed tuple) 的集合,然后利用 pattern 学习方法进行学习,通过不断迭代从非结构化数据中抽取实例。然后从新学到的实例中学习新的 pattern ,同时扩充 pattern 集合,寻找与发现新的潜在关系三元组。远程监督方法主要是对知识库与非结构化文本对齐来构建大量训练数据,减少模型对人工标注数据的依赖,增强模型的跨领域适应能力
Bootstrapping
- 收集一组具有关系 R 的 seed pair
- 迭代:
- 查找包含这些 pair 的 sentence
- 查看 pair 之间/周围的上下文,并将其概括以创建 patterns
- 使用 grep 的 patterns 获取更多 pair
Distant supervision
基本假设:两个实体如果在知识库中存在某种关系,则包含两个实体的非结构化句子均能表示出该种关系
步骤: 1. 从知识库抽取存在关系的实体对 2. 从非结构化文本中抽取含有实体对的句子作为训练样例,然后提取特征训练分类器
Distant Supervision 结合了 Bootstrapping 和监督学习的长处,使用一个大的 corpus 来得到海量的 seed example,然后从这些 example 中创建特征,最后与有监督的分类器相结合;与监督学习相似的是这种方法用大量特征训练了分类器,通过已有的知识进行监督,不需要用迭代的方法来扩充 pattern。 ;与无监督学习相似的是这种方法采用了大量没有标注的数据,对训练语料库中的 genre 并不敏感,适合泛化
如:PCNN + Attention
无监督学习¶
Unsupervised learning from the web
流程
1. Use parsed data to train a “trustworthy tuple” classifier
2. Single-pass extract all relations between NPs, keep if trustworthy
3. Assessor ranks relations based on text redundancy
事件抽取¶
与关系抽取相比,事件抽取同样需要从文本中抽取 predict 与其对应的 arguments,不同的是,关系抽取的问题是 binary 的,其两个 arguments 需在同一句中出现;而事件抽取则面对了了多个 arguments 和 modifiers,且可能分布在多个句子中,同时部分 arguments 可能不是必须的,这使得半监督学习中的几种方法应对该种情况时都比较困难
事件抽取的任务分为两大类:
-
事件识别和抽取
从描述事件信息的文本中识别并抽取出事件信息并以结构化的形式呈现出来,包括发生的时间、地点、参与角色以及与之相关的动作或者状态的改变
-
事件检测与追踪
事件检测与追踪旨在将文本新闻流按照其报道的事件进行组织,为传统媒体多种来源的新闻监控提供核心技术,以便让用户了解新闻及其发展。具体而言,事件发现与跟踪包括三个主要任务:分割,发现和跟踪,将新闻文本分解为事件, 发现新的(不可预见的)事件,并跟踪以前报道事件的发展;事件发现任务又可细分为 历史事件发现 和 在线事件发现 两种形式,前者目标是从按时间排序的新闻文档中发现以前没有识别的事件,后者则是从实时新闻流中实时发现新的事件
相关概念¶
- 事件描述 (Event Mention) 描述事件的词组/句子/句群,包含一个 trigger 以及任意数量的 arguments
- 事件触发 (Event Trigger) 事件描述中最能代表事件发生的词汇,决定事件类别的重要特征,一般为动词或名词
- 事件元素 (Event Argument) 事件的重要信息/实体描述 (entity mention),主要由实体、属性值等表达完整语义的细粒度单位组成
- 元素角色 (Argument Role) 事件元素在事件中扮演的角色,事件元素与事件的语义关系,可以理解为 slot
- 事件类型 (Event Type)
事件识别与抽取¶
类似于从文本中找到特定类别的事件,然后进行填表
Given a text document, an event extraction system should predict event triggers with specific sub-types and their arguments for each sentence.
事件抽取任务的基础部分包括:
- 识别事件触发词及事件类型
- 抽取事件元素,同时判断其角色
- 抽取描述事件的词组或句子
事件抽取大多是分阶段进行,通常是由 trigger classifier 开始,若有 trigger,就将 trigger 及其上下文作为特征进行分类判断事件类型,再判断下一步的 argument classifier,对句子中的每个 entity mention 进行分类,判断是否是 argument,如果是,则判定其角色
基于模式匹配的方法¶
核心:句法 (syntactic)、语义约束 (semantic constraints)
基于人工编写的规则/语法树/正则表达式
基于人工标注语料¶
- AutoSlog
基本假设
1. 事件元素首次提及之处即可确定该元素与事件间的关系
2. 事件元素周围的语句中包含了事件元素在事件中的角色描述
通过监督学习和人工审查来建立抽取规则。通过训练数据中已经填充好的槽(filled slot),AutoSlog 解析 slot 附近的句法结构,来自动形成抽取规则,由于这个过程产生的模板 too-general,所以需要人工来审核。本质上形成的是一个字典
- PALKA
基本假设
特定领域中高频出现的语言表达方式是可数的
基于弱监督¶
人工标注耗时耗力,且存在一致性问题,而弱监督方法则无需对语料进行完全标注,只需人工对语料进行一定的预分类或者制定种子模板,由机器根据预分类语料或种子模板自动进行模式学习
- AutoSlog-TS
- TIMES
- NEXUS
- GenPAM
基于模式匹配的方法在特定领域中性能较好,知识表示简洁,便于理解和后续应用,但对于语言、领域和文档形式都有不同程度的依赖,覆盖度和可移植性较差
模式匹配的方法中,模板准确性是影响整个方法性能的重要因素。在实际应用中,模式匹配方法应用非常广泛,主要特点是高准确率低召回率,要提高召回率,一是要建立更完整的模板库,二是可以用半监督的方法来建 trigger 字典
基于统计¶
建立在统计模型基础上,事件抽取方法可以分为 pipeline 和 joint model 两大类
基于统计 - Machine Learning¶
Pipeline
将事件抽取任务转化为多阶段的分类问题(管道抽取),需要顺序执行下面的分类器:
- 事件触发词分类器(Trigger Classifier)
判断词汇是否是事件触发词,以及事件类别 - 元素分类器(Argument Classifier)
词组是否是事件元素 - 元素角色分类器(Role Classifier)
判定元素的角色类别 - 属性分类器(Attribute Classifier)
判定事件属性 - 可报告性分类器(Reportable-Event Classifier)
判定是否存在值得报告的事件实例
分类器可以用 MaxEnt, SVM。重点还是在于提取和集成有区分性的特征,包括 句子级信息 和 篇章级信息
句子级信息:与候选词相关的词法特征、上下文特征、实体特征、句法特征、语言学特征等
篇章级信息:跨文档利用全局信息。对于一个句子级的抽取结果不仅要考虑当前的置信度,还要考虑与待抽取文本相关的文本对它的影响,以及全局信息如事件与话题的关系,事件与事件的共现信息等
Joint Model
分为 Joint Inference 和 Joint Modeling 两种
Joint Inference 使用集成学习的思路,将各模型通过整体优化目标整合起来,可以通过整数规划等方法进行优化
Joint Modeling (Structured) 又可以称为基于结构的方法,将事件结构看作依存树,抽取任务相应转化为依存树结构预测问题,触发词识别和元素抽取可以同时完成,共享隐层特征,使用搜索进行求解,避免了误差传播导致的性能下降,另外,全局特征也可以从整体的结构中学习得到,从而使用全局的信息来提升局部的预测
基于统计 - Deep Learning¶
上面的方法在特征提取过程中还是会依赖依存分析、句法分析、词性标注等传统的外部 NLP 工具,还是会造成误差积累,另外有些语言和领域并没有这类处理工具,加之特征也需要人工设定,2015 年起基于深度学习的事件抽取方法逐渐成为研究热点,相比于传统机器学习,深度学习方法优势明显:
- 减少对外部 NLP 工具的依赖 , 甚至不依赖 NLP 工具 , 建立成端对端的系统
- 使用词向量作为输入,蕴含更为丰富的语言特征
- 自动提取句子特征, 避免了人工特征设计的繁琐工作
Pipeline
DMCNN
Joint Model
JRNN
弱监督 / 预料拓展¶
有监督的方法需要大量的标注样本,人工标注耗时耗力,还存在一致性的问题,因此弱监督方法也是事件抽取的一个重要分支
弱监督/训练数据生成方面比较流行的方向有 利用外部资源,通过远程监督,以及跨语料迁移的方法
事件检测与追踪¶
主流方法包括基于相似度聚类和基于概率统计两类
Created: 2023-07-29