Summary
论文 1:KGE¶
An Overview of Methods and Tools for Extraction of Knowledge for COVID-19 from Knowledge Graphs¶
从知识图谱中提取 COVID-19 知识的方法和工具概述
Abstract
本文定义了可用于 COVID - 19 信息的搜索引擎的总体描述。对 COVID - 19 信息的知识图谱进行简要综述,并介绍了基于知识图谱的严重特殊传染性肺炎知识抽取和理解的主要相关方法。在此基础上,提出了一种面向 COVID - 19 的知识推理方法。
Keywords
Knowledge graph · COVID-19 · Extraction of information · Reasoning · Information searching · Artificial intelligence · Web search · Information retrieval
Introduction
- Section 1:关于 COVID-19 的搜索系统与指示图谱综述
- Section2:构建 COVID-19 知识图谱可能面临问题
- Section 3 and 4:COVID-19 信息推理算法使用分类
Section 1
简要介绍了目前关于 COVID-19 的搜索系统(类型、特点、构建方式等)以及知识图谱
Section 2
- 数据约束:疫情不断扩大造成的数据集不断增多且变化;嵌入知识与同其他疾病相关性的不断变化;疫情扩散对于数据显示方面的影响;
- 数据质量:数据质量影响着知识图谱的可信度以及输出的准确度,以及其与搜索系统的结合
- 规模约束:数据增加至一定量后(Big data),其分布就趋于稳定;大数据与私人企业隐私的冲突
- 数据呈现:可视化效果好坏
- 社会约束:新技术对保守用户的冲击
Section 3 and 4
-
KG中知识推理的 COVID-19 的抽取应用定义
- 知识推理:从信息抽取中利用已知知识推理出新知识的过程
- 早期的推理学习由逻辑学及知识工程领域的专家进行,这一时期的知识图谱也是由专家进行标注
- 随着互联网造成的数据规模的爆炸式增长,传统人工构建方式已经不能适应大量知识挖掘的需要,基于数据驱动的机器推理方法成为主流
- 随着知识图谱的发展,对知识图谱的推理也愈发受到关注
-
基于知识图谱的 COVID-19 知识推理通用模型
知识图谱推理可以被定义为以下任务: + 缺失实体预测:已知实体 N1 与关系 R,预测缺失实体 N2 + 缺失联系预测:已知 2 个实体,预测其关系 + 事实预测:从三元组预测事件 F 为 true 或 false
-
面向 COVID-19 实体抽取的分类知识推理
(1) 基于逻辑规则的知识推理 + 基于规则的知识推理 + 基于事例的知识推理(从事例中推断实体关系) + 基于本体的知识推理(构建本体,进行训练) + 基于随机游走算法的知识推理(随机游走算法识别知识图谱中的关系)
(2) 基于分布式表示的知识推理 + 基于张量分解的知识推理 + 用于知识图谱嵌入的张量矩阵框架 + 语义匹配模型上的知识推理 + 基于多源信息的知识推理
(3) 基于神经网络的知识推理 + 卷积神经网络 + 模糊干扰与深度神经网络的混合推理模型 + 基于注意力的图卷积网络的预测模型
论文 2:KGE¶
TEBC-Net: An Effective Relation Extraction Approach for Simple Question Answering over Knowledge Graphs¶
TEBC-Net:一种基于知识图谱的简单问答的有效关系提取方法
Abstract
知识图谱简单问答 (KGSQA) 旨在通过对知识图谱上单个实体的查找来回答自然语言问题,而关系抽取作为其核心人物之一,对最终答案的质量有着重要影响。为提高 KGSQA 中关系抽取任务的准确率,本文提出了一种新的深度神经网络模型 TEBC-Net,该模型基于 Transformer Encoder、BiLSTM 以及 CNN net,并由上述几种模型进行无缝结合构建。并通过基准测试验证了其准确率较高。
Keywords
Knowledge graph simple question answering · Relation extraction · Natural language processing · Deep learning · TEBC-Net
Introduction
知识图谱是真实世界实体之间相互联系的抽象表示。但因为知识图谱中包含的大量数据,除非熟悉相关的查询语法,一般用户很难有效的在知识图谱中检索有价值的信息。为应对该问题,弥补语义差距,知识图谱问答器 (KGQA) 被提出。KGSQA 即是该领域的典型研究问题,它侧重于通过对 KG 中单个事实的查找来回答简单问题。
对于 KGSQA,知识抽取 (在某种类型的两个或多个实体中抽取语义联系) 是其中的一项重要任务。知识抽取可以被用来提取自然语言询问中的原始结构信息,并在其基础上构建 KG 查询。
为了提高 KGSQA 中 RE (关系抽取) 的准确度,本文提出了基于 Transformer Encoder、BiLSTM 以及 CNN net 无缝结合的深度神经网络模型 —— TEBS-Net。具体地,首先,引入 knowledge graph embedding (KGE) 算法对 KG 中的事实进行编码;其次,对于给定的问题,使用 BiLSTM 捕获上下文信息,并利用 Transformer 中编码模块的自注意力机制去抽取关键信息;之后,使用 CNN 捕获问题的字符信息,并再次利用自注意力机制提取关键信息已完成知识抽取。实验表明,其优化效果较为明显。
文章的结构如下:
- Section 2:相关工作
- Section 3:TEBC-Net 的详细结构与实现
- Section 4:实验结果
- Section 5:总结与前景
Section 2
-
KGQA
-
基于模板的问答方法(预定义模板匹配、形式化查询)(模板生成成本高、数量有限)
-
基于端到端的深度学习的 KGQA 方法(多通道 CNN 提取关系,将关系短语映射到知识库谓词)
-
RE
-
传统分类 RE
- 深度学习模型
The Proposed TEBC-Net for KGSQA
对于知识图谱所能回答的所有问题,必须将关系的向量表示提前投影到关系嵌入空间中,该种情况下,将 KGSQA 的过程分为 3 步:
-
使用知识图谱嵌入 (KGE) 将 KG 中的每个实体与关系作为低维向量
- 使用低维向量嵌入知识图谱是 KGSQA 中典型的预处理方法
- KGE 将 KG 中每个实体与关系表示为一个低维向量,并能以数值向量的形式保持 KG 原有的结构与关系
- 对于简单问题(一个头实体与一个关系),使用 TransE 模型
-
将问题作为输入,输入至 TEBC-Net,返回一个映射向量,计算两向量间的向量空间距离并进行排序,完成 RE
-
对于给定问题进行知识抽取,方法中考虑下述三项核心因素:词的全局特征、词的字符特征、词的重要性
-
Transformer Encoding layer 中的 self-attention mechanism 对词语重要性过滤编码
-
CNN 表示待编码问题特征
-
BiLSTM 双向机制代替 Transformer 三角位置编码,以对生成词上下文序列正确编码
- 在语序编码过程中可同时表示绝对位置与相对位置
- Transformer 三角函数位置嵌入可检查单词之间的距离,但是忽视了单词的相对方向
-
TEBC - Net
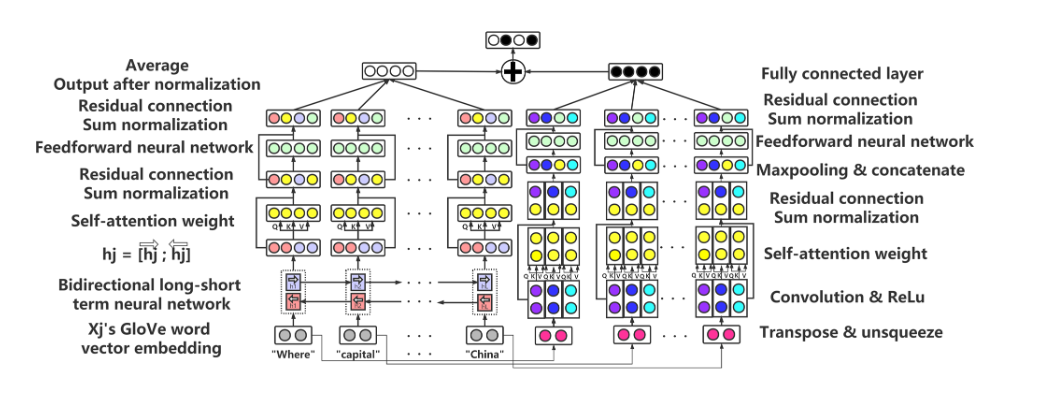
-
Left Part —— Global Features with Importance
- 联合 BiLSTM 与 self-attention 对问题进行编码
-
Right Part —— Character Features with Importance
- 联合 CNN 与 self-attention 对问题进行编码
-
基于提取的关系进行 KGSQA
- 在 KEQA 框架下,在 KG 中与 QA 有关系的任务主要有三个 (HED)
- 头部实体识别
- 关系抽取
- 头部实体检测
- 在 KEQA 框架下,在 KG 中与 QA 有关系的任务主要有三个 (HED)
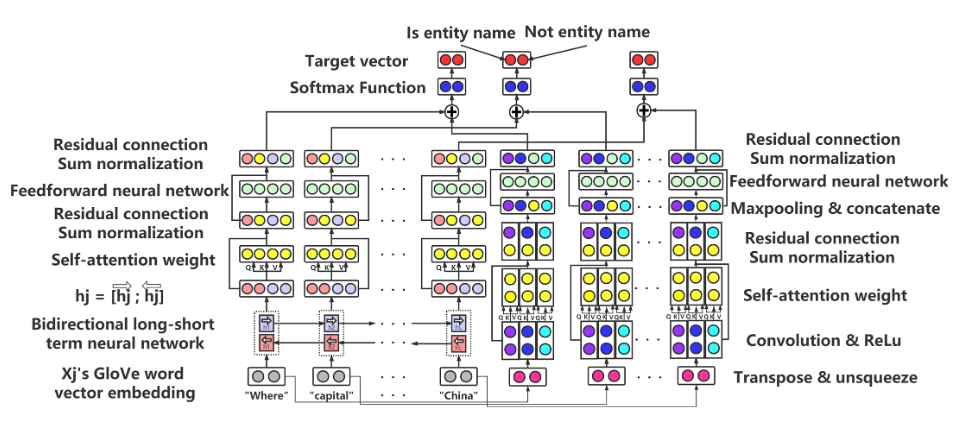
Conclusion
类似于 Introduction
论文 3:Survey、常识性知识¶
Information to Wisdom: Commonsense Knowledge Extraction and Compilation¶
信息到智慧:常识性知识的提取与汇编
Abstract
常识性知识是人工智能应用的基石。虽然 (Whereas) 面向实例断言的信息抽取与知识库构建已经得到较多关注,但关于一般概念与活动的的常识性知识,最近才得到解决。在本教程 (tutorial) 中,我们提出了最先进的方法来汇编与巩固这些常识知识。涵盖了基于文本抽取、多模态以及基于 Transformer 的技术,特别关注 (with speical focus on) 与 WSDM 社区相关的网络搜索与排名问题。
Motivation
Overview
常识知识 (CSK) 对于建立多功能只能应用至关重要。在以命名实体为中心的百科知识划定中,常识被用来指代一般概念之间的属性、特征与关系。CSK 的机器可读集合对于实现问答以及自然交流非常重要。
结构化常识知识与预训练语言模型的最新进展相互作用:后者可以用来生成流畅的自然语言,而前者对于将语言生成限制在合理且连贯的语句的范围内也颇为重要。特别是对于工业应用,结构化常识为防止一些应用问题提供了可解释、可辨认的资源。
Brief Outline Of Topic
-
简介 (Introduction)
- 什么是 CSK?为什么 CSK 这么重要?是什么令其编译具有挑战性?
- 激发 CSK 在对话与其它应用中的相关性,并将其与小数据用例相联系
- 编译面临获取 (reporting bias etc.)、聚合 (incoherence etc.)以及应用 (mismatches between structured data and neural networks)
- 知识表示
- CYC 项目中使用的表达模态 (expressive modal) 以及认知逻辑
- 语义 Web 项目中流行的单维得分三元组
- 非结构化文本与预训练语言模型中的分布式表示
- 历史
- CSK 研究的根源
- 早期项目:CYC、WordNet 以及 ConceptNet
- 用例历史:百科全书问答 ——> 常识推理
- 什么是 CSK?为什么 CSK 这么重要?是什么令其编译具有挑战性?
-
文本抽取 (Text extraction)
- Recipe:介绍从文本中提取、合并 CSK 的方法
- Source selection (数据源选择)
- popular resource:Wikipedia、open web crawls、scientific documents、QA-Forums etc.
- 讨论数量、质量、真实性、显著性的权衡
- Extraction paradigm (抽取范式)
- 对流行的抽取范式分类
- 规范化 (canonicalized) || 开放关系 (open relation) 抽取 || 主客体规范化
- 实体 (entity) || 活动 (activity) || 面向属性 (property-oriented) 的对象
- 提出自然语言处理的核心底层概念
- 对流行的抽取范式分类
- Consolidation (合并)
- 整合初始抽取的必要性
- 综述基于标签传播 (label propagation)、多源验证 (multi-source validation)、软约束推理 (soft constraint reasoning) 的突出方法
- Source selection (数据源选择)
- 案例研究
- Recipe:介绍从文本中提取、合并 CSK 的方法
-
多模态知识 (Multimodel knowledge)
描述了在视觉与文本的 KG 中呈现互补知识的论文。例如视觉常识库就在视觉问答中提供解释。同时讨论了从现实世界隐式、显式收集常识的方法
-
基于深度学习的技术 (Deep learning based techniques)
-
神经网络作为知识源
有证据证明,神经语言模型包含部分类型的 CSK,但同时不包含其他类型的知识。这些神经结构可以通过现有的符号 KG 进行增强,以使模型能够泛化知识,或是在多模态数据上学习视觉与语言的通用表示。然后,讨论如何通过将概率质量 (probability mass) 从难置信的 (implausible) w.r.t CSK 输出上移除,以在神经模型中融入符号性知识。这些模型在认为其存在数据缺口时,可以自动咨询外部知识。
-
用于通用知识编译与应用的神经模型
能否将知识、符号、神经等多种异质资源结合起来?一篇 paper 中提出使用基于注意力的组合方法,而当前方法则是训练用于多任务学习的单一模型,我们讨论这些不同方法的优缺点
-
-
获取知识评价 (Evaluation of the acquired knowledge)
- 获取的知识质量是否够好? 回顾内在质量 (intrinsic quality) 的维度,以及注释任务的适当设置
- 获取的知识是否可用?
-
亮点、展望与开放问题 (Highlights, Outlook and Open Issues)
Relevance To The Community
常识性知识相关焦点教程:
-
Commonsense Reasoning for Natural Language Processing, Sap et al., ACL 2020.
该教程以 NLP 为中心,强调推理,通常通过情境式多选题回答进行评估。展示了围绕 Transform 架构构建的前沿技术,但对可解释的 CSK 集合关注较少。
-
Common Sense Knowledge Graphs (CSKGs), Ilievski et al, ISWC 2020.
该文献针对语义 Web 社区。重点研究了 CSK 的链接数据方面,及其高效集成与利用
论文 4:Survey、KBQA、KR¶
A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions¶
Abstract
知识库问答 (KBQA) 旨在通过知识库进行问答。近来,大量研究更加关注语义/句法复杂的问题。在本篇 paper 中,作者详尽的总结了复杂 KBQA 面临的各类挑战及其解决措施。文章由介绍 KBQA 任务的背景开始。其次介绍两类主流的复杂 KBQA 方法:基于语义解析 (SP-based) 的方法 以及 基于信息检索 (IR-based) 的方法。然后,从上述两个类别的角度全方面回顾了先进方法。具体而言,作者们在问中阐述了各类方法对典型挑战的解决方案。最后,推断与讨论未来研究的发展方向
Introduction
KB 是一个包含 (subject, relation, object) 事实的集合的结构化知识库,常见的大规模 KB 有: Freebase、DBPedia、Wikidata,他们已经被用来构建许多下游任务。在可利用 KB 的 基础上,KBQA 是以KB 为知识源,回答自然语言问题的任务。KBQA 的早期任务关注回答只含单一事实的简单问题。
近来,研究者更关注于通过 KB 来回答复杂问题。复杂问题通常都包含多个主体,表现混合的关系并且包含数值运算。
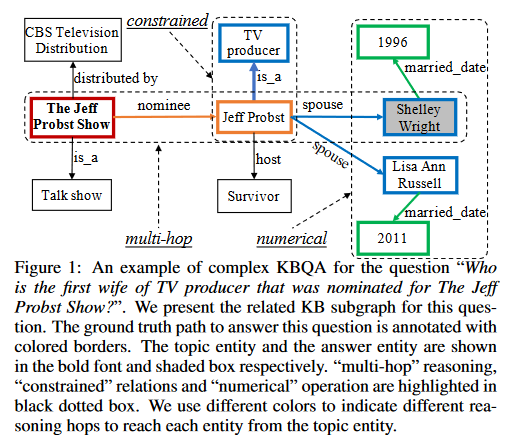
This example question starts with the subject “The Jeff Probst Show”. Instead of querying a single fact, the question requires the composition of two relations, namely, “nominee” and “spouse”. This query is also associated with an entity type constraint “(Jeff Probst, is a, TV producer)”. The final answer should be further aggregated by selecting the possible candidates with the earliest marriage date. Generally, complex questions are questions involving multi-hop reasoning, constrained relations, numerical operations, or some combination of the above.
回到对于简单 KBQA 的解决方式,来自上文两种主流方法的大量研究被提出。这两种方法首先识别问题中的主体,然后将其与 KB 中的实体进行链接。然后,他们通过执行解析的逻辑表单或在从 KB 中抽取的特定问题的图上进行推理,从而在主题实体的邻域获得答案。
他们包含不同的工作机制来解决 KBQA 任务。SP-based 以符号逻辑形式表示一个问题,然后对 KB 执行从而获取最终答案。IR-based 则构建一个问题特定图来传递与问题相关的综合信息并根据问题的相关性对抽取图中的所有实体进行排序。
复杂问题对方法提出挑战:
- 现有 SP-based 使用的解析器难以覆盖多样化的复杂查询。而以前 IR-based 方法可能无法回答复杂的查询,因为它们的排序是在小范围实体上进行的,没有可追踪的推理。
- 复杂问句中更多的关系和主语预示着解析潜在逻辑形式的搜索空间更大,这将大大增加计算成本。同时,更多的关系与主体对 IR 相关实体排序造成阻碍
- 两种方法都以问题理解作为首要步骤,但当问题在语义与符号层面趋于复杂,model 也被要求对自然语言理解、概括方面有更高的能力
- 对于复杂问题,将基本真值路径标注到答案是昂贵的。一般只提供问答对。这表明 SP-based 和 IR-based 分别需要在没有正确逻辑形式和推理路径标注的情况下进行训练。如此微弱的监督信号给两种方法都带来了困难。
2 Background
介绍任务制定的初级知识,以及多个可用数据集和评估协议
Tasks
对于复杂 KBQA 的任务,给定一个由一组事实组成的 KB 作为输入, 其中主体与客体通过其关系进行链接。事实中的所有主体和对象构成了 KB 的实体集。考虑到可用的知识库,复杂 KBQA 任务旨在以 sequence of tokens 的格式回答复杂的自然语言问题。特别地,我们假设正确答案来自 KB 的实体集合。与简单 KBQA 的答案不同,这些答案是直接连接到主题实体的实体,而复杂 KBQA 任务的答案是距离主题实体多跳的实体,甚至是它们的一些聚合。
Datasets
通常来说,为了训练一个复杂的 KBQA 系统应该提供问题的答案。因此,针对复杂 KBQA 数据集的构建,做了很多工作。可用 (常用) 的数据集如下:
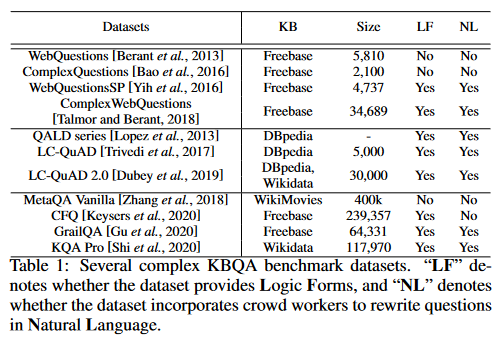
总体而言,这些数据集是通过以下步骤构建的:
- 给定 KB 中的一个主题实体作为问题主体
- 首先用不同的模板创建简单的问题
- 基于简单问题和知识库中主题实体的邻域,用预定义的模板进一步生成复杂问题,一些工作也用模板生成可执行的逻辑形式。同时,用相应的规则提取答案
在某些情况下,雇佣工作者将模板查询复述为自然语言问句并对生成的逻辑形式进行细化,使得问句表达更加多样化和流畅。为了服务于现实的应用,这些数据集通常创建需要多个KB事实来推理的问题。此外,它们可能包括数值运算以及约束,这进一步增加了从知识库中推理答案的难度。
Evaluation Protocol
KBQA 系统通常预测置信度得分最高的实体形成答案集。这也同时告诉我们,对一个问题我们可以产生多个答案。在以往的研究中,有一些经典的评价指标,如:精确率、召回率、F1和 Hits@1。准确率表示正确答案占所有预测答案的比例,召回率是正确预测答案占所有真实答案的比例。
3 Two Mainstream Approaches
上述两种方法遵循着解析-执行范式 (parse-then - excute) 或检索-排序范式 (retrieval-and-rank)
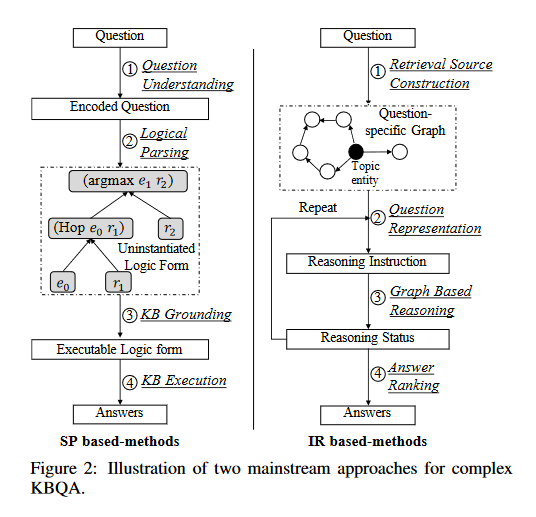
Semantic Parsing-based Methods
该类方法旨在将自然语言解析为逻辑形式。主要通过以下步骤进行对问题进行预测解答:
- 他们通过 question understanding 模块来完全理解一个问题 (进行语义、句法分析),得到一个编码后问题,用于后续的解析步骤
- logical parsing 模块被用来将编码后问题转化为非实例化的逻辑形式。非实例化的逻辑形式是问题的句法表征,没有实体与关系基础。逻辑形式的语法和成分可以根据系统的具体设计而有所不同
- 为了对 KB 执行,通过 KB grounding 模块对结构化 KBs 进行一些语义对齐,进一步实例化、验证逻辑形式
- 解析后的逻辑形式通过对 KBs 执行 KB execution 模块以生成预测答案
Information Retrieval-based Methods
该类方法直接从知识库中检索答案,并根据问题所传达的信息对答案进行排序。步骤如下:
- 由主题实体 (topic entity) 出发,系统首先从 KBs 中抽取出特定问题图。该图包含着所有问题的相关实体与关系,并分别将其作为节点与边。没有显式生成可执行的逻辑形式,而是对图进行推理,然后对图中的实体进行排序
- 其次,系统通过 question representation 模块对输入问题进行编码。该模块分析问题的语义并输出推理指令,通常以向量的形式表示
- graph-based reasoning 模块通过基于向量的计算进行语义匹配,将信息沿着图中的相邻实体进行传播和聚合。推理状态是在推理指令的基础上更新的,在不同的方法 (例如,预测实体的分布、关系的表示) 中有不同的定义。
- answer ranking 在推理结束时根据推理状态对图中实体进行排序。排名靠前的实体被预测为问题的答案。
Pros and Cons (优缺点)
总的来说,SP-based methods 可以通过生成表达性逻辑形式,产生更具可解释性的推理过程。然后,他们很大程度上依赖于逻辑形式与解释算法的设计,这导致性能改进遇到瓶颈。
与之比较,IR-based methods 对图结构进行复杂推理并进行语义匹配。这样的范式很自然地适合流行的端到端训练,使得该模型更容易训练。然而,推理模型的黑箱风格使得中间推理的可解释性较差。
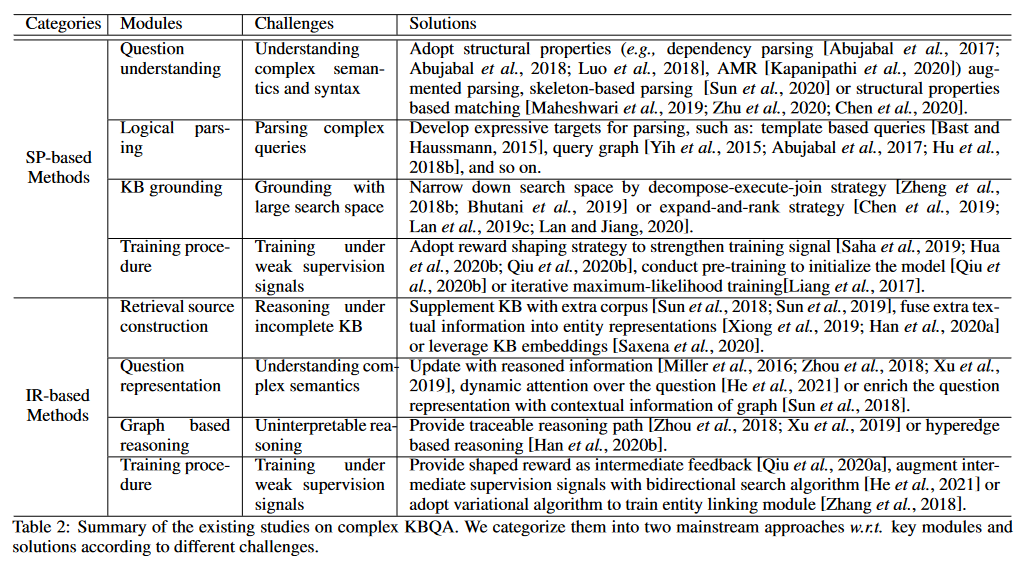
4 Challenges and Solutions
由于上述方法是基于不同的范式发展起来的,下面将分别介绍两种主流方法在复杂KBQA中面临的挑战和相应的解决方案。下表总结了这些挑战和解决方案。
5 Conclusion and Future Directions
本文试图提供关于复杂 KBQA 的典型挑战和相应解决方案的概述。我们介绍了常用的数据集并总结了广泛使用的基于 SP 的方法和基于 IR 的方法。现有的复杂 KBQA 方法一般归纳为这两类。除此之外,其他一些方法能不属于这两类。例如,通过基于规则的分解将复杂问题转化为简单问题的组合方法,该方法侧重于问题分解,而不是基于 KBs 的推理或逻辑形式生成。我们相信,复杂知识库问答系统将继续成为一个活跃的、具有广阔应用前景的研究领域,如自然语言理解、组合泛化、多跳推理等。这项调查中提出的许多挑战仍然是开放的和探索不足的
Created: 2023-07-29